Inferring the 3D structure underlying a set of multi-view images typically requires solving two co-dependent tasks -- accurate 3D reconstruction requires precise camera poses, and predicting camera poses relies on (implicitly or explicitly) modeling the underlying 3D. The classical framework of analysis by synthesis casts this inference as a joint optimization seeking to explain the observed pixels, and recent instantiations learn expressive 3D representations (e.g., Neural Fields) with gradient-descent-based pose refinement of initial pose estimates. However, given a sparse set of observed views, the observations may not provide sufficient direct evidence to obtain complete and accurate 3D. Moreover, large errors in pose estimation may not be easily corrected and can further degrade the inferred 3D. To allow robust 3D reconstruction and pose estimation in this challenging setup, we propose SparseAGS, a method that adapts this analysis-by-synthesis approach by: a) including novel-view-synthesis-based generative priors in conjunction with photometric objectives to improve the quality of the inferred 3D, and b) explicitly reasoning about outliers and using a discrete search with a continuous optimization-based strategy to correct them. We validate our framework across real-world and synthetic datasets in combination with several off-the-shelf pose estimation systems as initialization. We find that it significantly improves the base systems' pose accuracy while yielding high-quality 3D reconstructions that outperform the results from current multi-view reconstruction baselines.
Given estimated camera poses from off-the-shelf models (e.g., DUSt3R, Ray Diffusion, and RelPose++), our method iteratively reconstructs 3D and optimizes poses leveraging diffusion priors. To address initial camera poses with significant errors (i.e., outliers), we identify them by checking if their involvement in 3D inference yields larger errors in other views, implying the inconsistency of their poses with others.

Explore our GitHub Repository to set up the demo on your machine! You can run our model in two ways:
Once the preprocessed images are displayed, click Run Single 3D Reconstruction. If the resulting 3D reconstruction appears inaccurate, use Outlier Removal & Correction to handle potential outlier camera pose(s) using our full method and improve the results. A video demonstration is provided below.
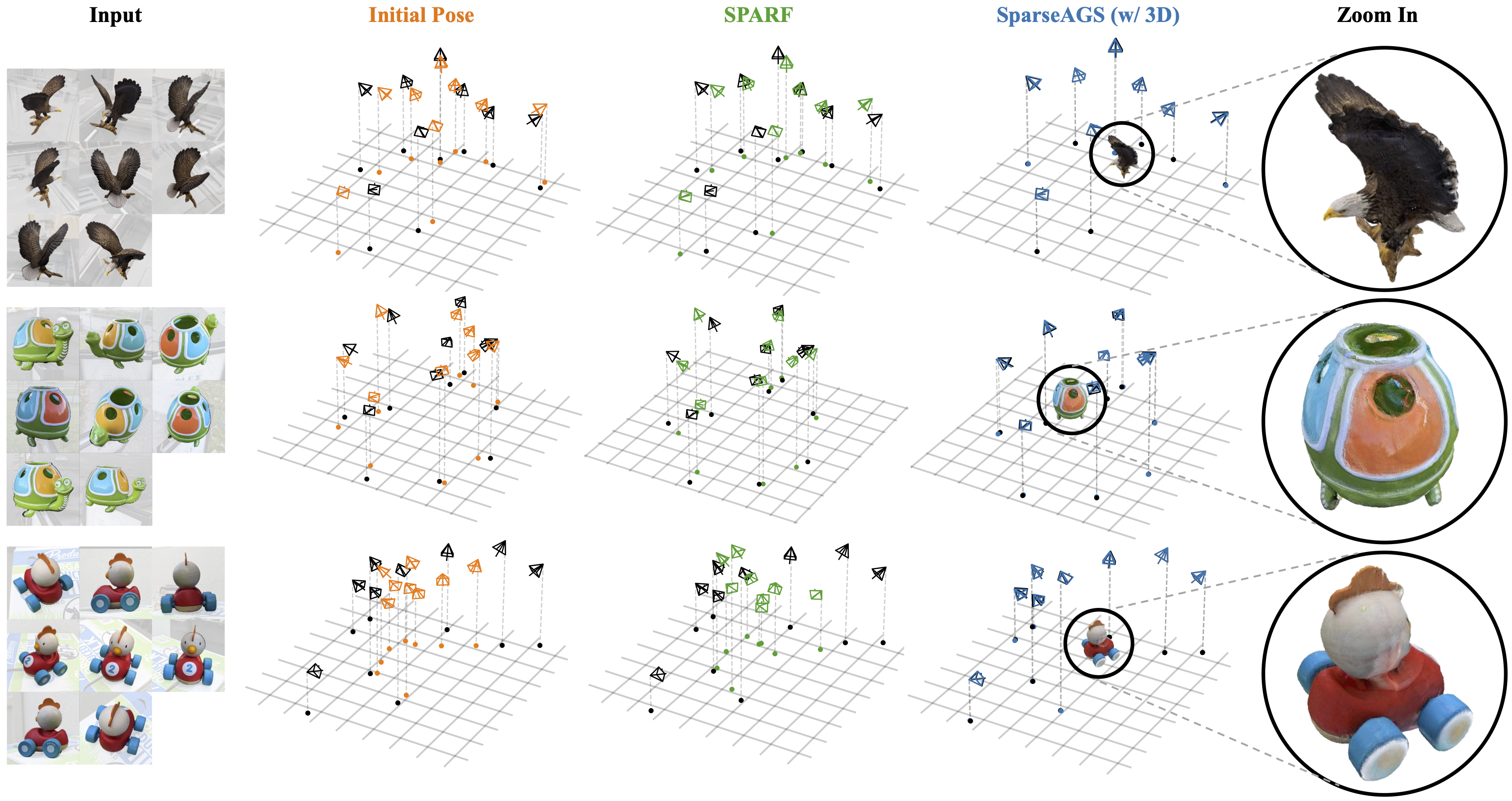
We compare DiffusionSfM on pose accuracy with SPARF. Our method can deal with initial camera poses with large errors.
We compare DiffusionSfM on novel view synthesis with LEAP. Our method can preserve high-quality details from input images. Please refer to our paper for more comparisons with SPARF and UpFusion.

@inproceedings{zhao2024sparseags,
title={Sparse-view Pose Estimation and Reconstruction via Analysis by Generative Synthesis},
author={Qitao Zhao and Shubham Tulsiani},
booktitle={NeurIPS},
year={2024}
}
Our 3D reconstruction pipeline is built on top of DreamGaussian and Stable-DreamFusion. Additionally, we fine-tuned and utilized the novel-view generative priors from Zero123. We sincerely appreciate the authors' efforts in open-sourcing their code.
We thank Zihan Wang and the members of the Physical Perception Lab at CMU for their valuable discussions. We especially appreciate Amy Lin and Zhizhuo (Z) Zhou for their assistance in creating figures, as well as Yanbo Xu and Jason Zhang for their feedback on the draft. We also thank Hanwen Jiang for his support in setting up the LEAP baseline for comparison.
This work was supported in part by NSF Award IIS-2345610. This work used Bridges-2 at Pittsburgh Supercomputing Center through allocation CIS240166 from the Advanced Cyberinfrastructure Coordination Ecosystem: Services & Support (ACCESS) program, which is supported by National Science Foundation grants #2138259, #2138286, #2138307, #2137603, and #2138296.