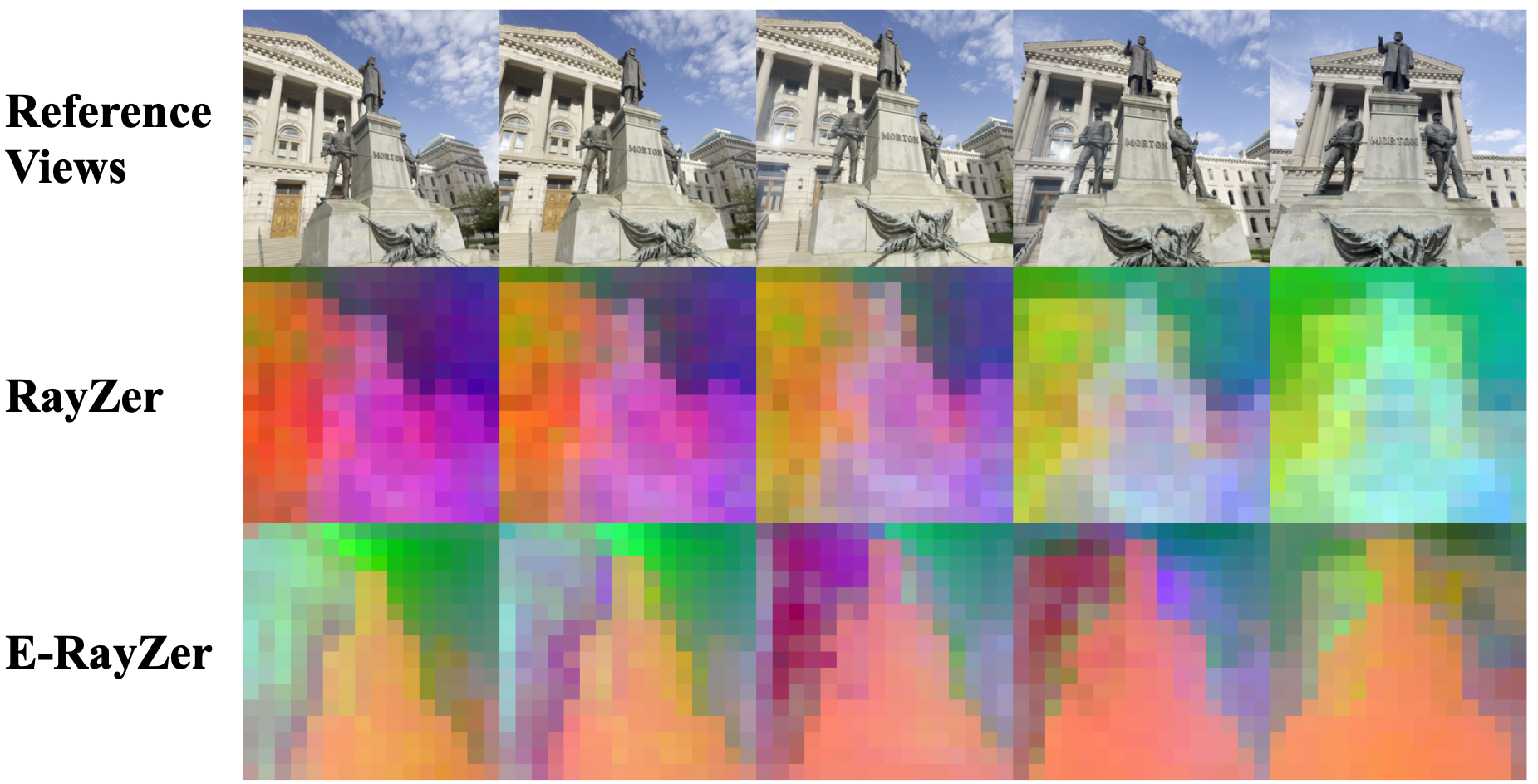
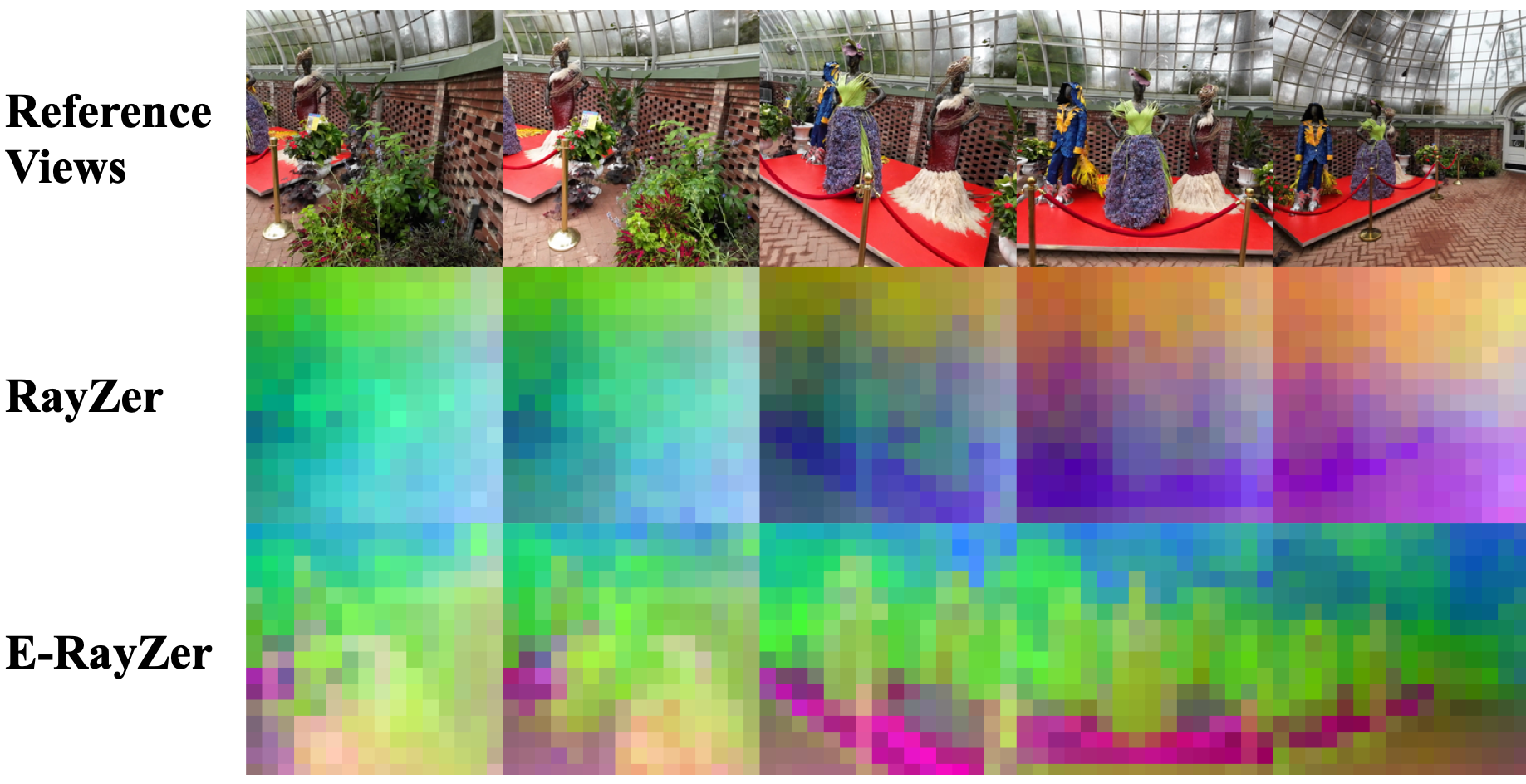
We visualize the features of RayZer and E-RayZer using PCA. E-RayZer learns spatially coherent image representations with better object discrimination.
Self-supervised pre-training has revolutionized foundation models for languages, individual 2D images and videos, but remains largely unexplored for learning 3D-aware representations from multi-view images. In this paper, we present E-RayZer, a self-supervised large 3D Vision model that learns truly 3D-aware representations directly from unlabeled images. Unlike prior self-supervised methods such as RayZer that infer 3D indirectly through latent-space view synthesis, E-RayZer operates directly in 3D space, performing self-supervised 3D reconstruction with Explicit geometry. This formulation eliminates shortcut solutions and yields representations that are geometrically grounded. To ensure convergence and scalability, we introduce a novel fine-grained learning curriculum that organizes training from easy to hard samples and harmonizes heterogeneous data sources in an entirely unsupervised manner. Experiments demonstrate that E-RayZer significantly outperforms RayZer on pose estimation, matches or sometimes surpasses fully supervised reconstruction models such as VGGT. Furthermore, its learned representations outperform leading visual pre-training models (e.g., DINOv3, CroCo v2, VideoMAE V2, and RayZer) when transferring to 3D downstream tasks, establishing E-RayZer as a new paradigm for 3D-aware visual pre-training.
Model & Training: E-RayZer first predicts camera poses and intrinsics for all images. Then it follows RayZer to split images into two sets. E-RayZer predicts explicit 3D Gaussians as scene representation from the reference views, and renders the scene using self-predicted target-view cameras. Finally, E-RayZer is trained with self-supervised photometric losses on target views.

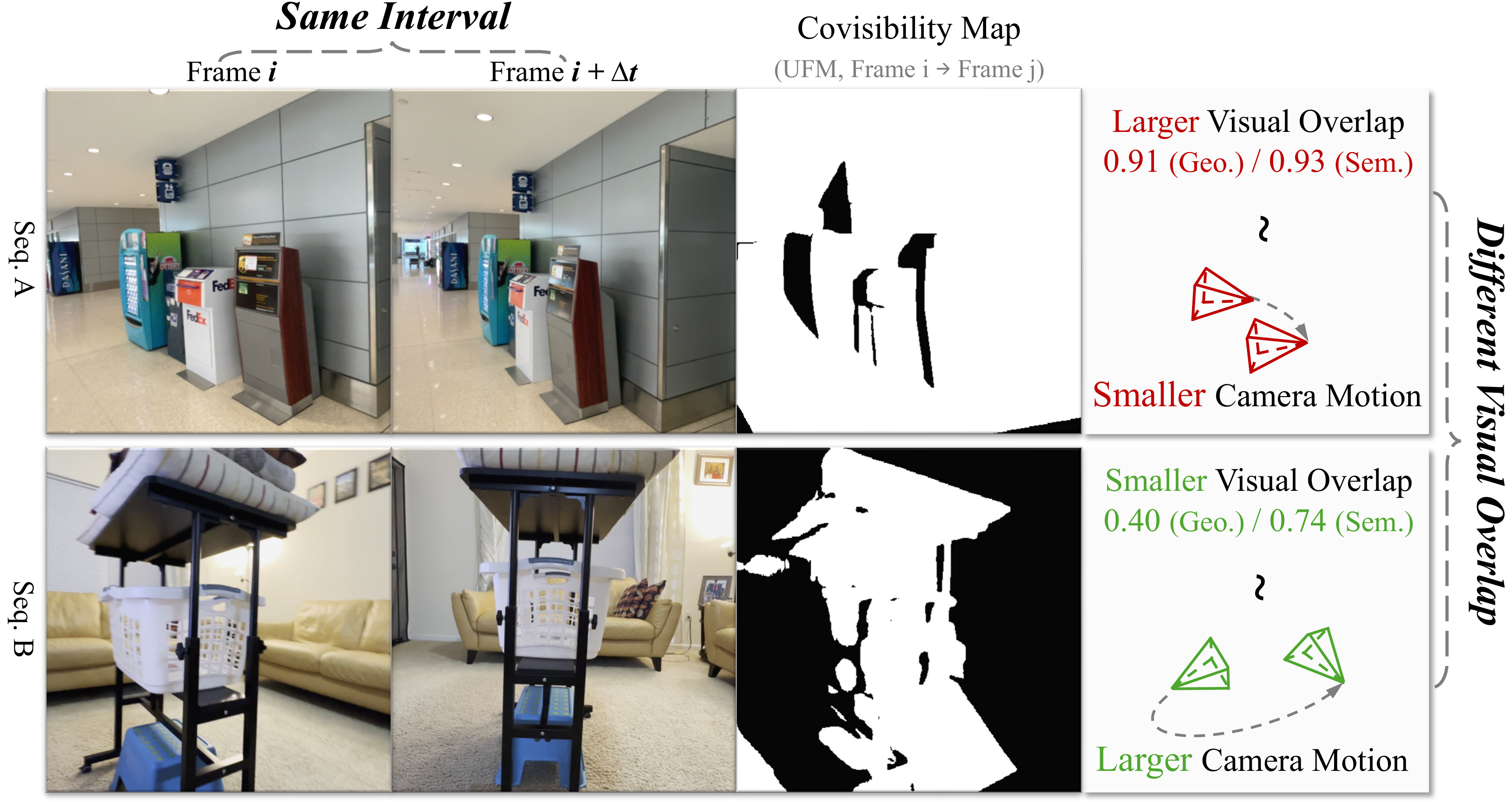
Learning Curriculum: Directly training the model from scratch often fails. We propose a learning curriculum based on visual overlap between images, organizing training from easy to hard samples and harmonizing heterogeneous data sources as we scale up. We approximate visual overlap using DINO embeddings, which we find to be a better proxy than frame interval.
Trained purely self-supervised without any 3D annotations, E-RayZer produces highly accurate 3D reconstructions (Gaussian centers visualized as a point cloud).








(Comparisons on Novel View Synthesis and Pose Estimation)
Ground-truth poses are visualized in black, and predicted poses are aligned to the ground truth via an optimal similarity transform. E-RayZer outperforms baselines in pose accuracy, demonstrating more geometrically grounded 3D understanding. While RayZer typically produces high-quality novel views, it often exhibits grid-like artifacts in complex regions (highlighted with red boxes), suggesting it may rely on unwanted interpolation cues to facilitate view synthesis.

We observe that SPFSplat struggles with wide-baseline inputs. RayZer can synthesize high-quality novel views, but frequently introduces visible artifacts (particularly noticeable in examples 4 and 8) -- especially in regions with high uncertainty, occlusion, or large viewpoint changes, highlighting its imperfect 3D understanding. These artifacts typically manifest as flickering surfaces and unstable geometry. In contrast, E-RayZer produces more accurate and stable renderings, benefiting from its explicit 3D geometry representation.
(Comparisons on Representation Learning)
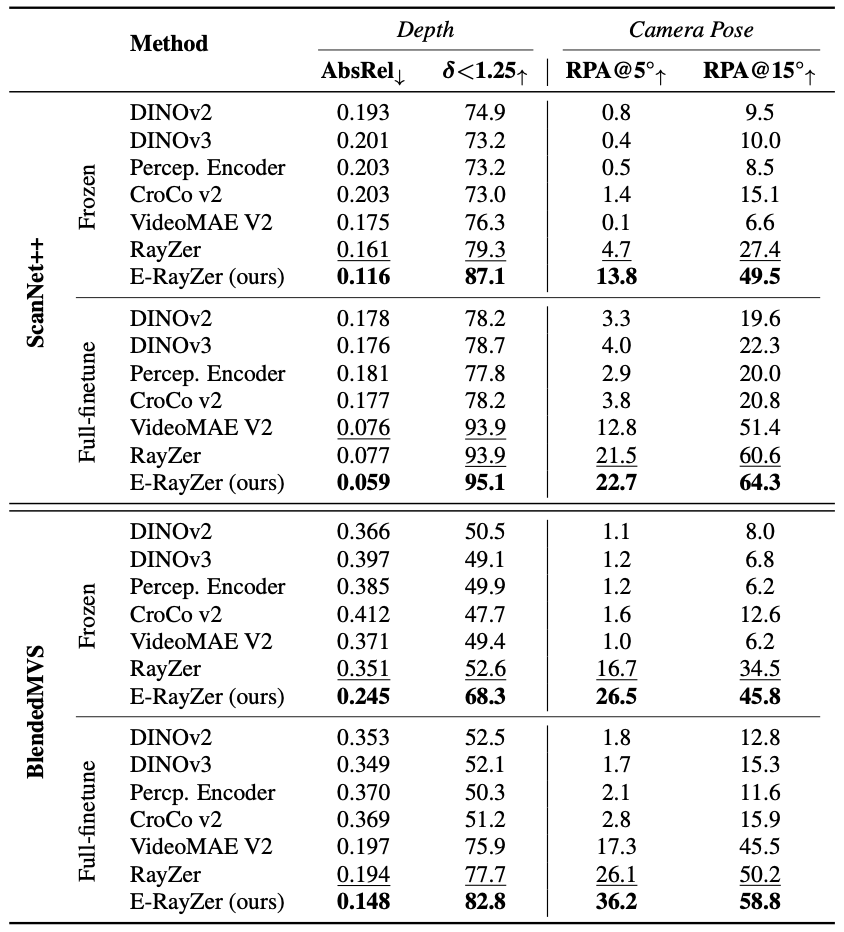
(Left) Results on 3D Tasks (Multi-view Depth and Pose Estimation). We evaluate the learned representations via both frozen-backbone and fully supervised finetuning. We fine-tune on ScanNet++ and BlendedMVS, which are not included in pre-training for any model. The best results are shown in bold, and the second-best are underlined.
(Right) Results on 2.5 Task (Pairwise Flow Estimation). We evaluate on StaticThings3D, an out-of-distribution synthetic dataset. All models are fully finetuned under flow supervision. The best results are shown in bold, and the second-best are underlined.

We visualize the features of RayZer and E-RayZer using PCA. E-RayZer learns spatially coherent image representations with better object discrimination.



(And Self-supervised E-RayZer Scales Well!!!)
We compare E-RayZer against supervised VGGT* (re-trained by us under the same settings) across different training data scales. For each model, we color-rank results from red to yellow across data scales, so the color distribution reflects its scaling behavior. We underline cases where self-supervised E-RayZer outperforms supervised VGGT*.
In addition, E-RayZer improves supervised models when used for pre-training (last row of each data setting), supporting an effective self-supervised pre-training + supervised fine-tuning paradigm.

@inproceedings{zhao2026erayzer,
title = {E-RayZer: Self-supervised 3D Reconstruction as Spatial Visual Pre-training},
author = {Qitao Zhao and Hao Tan and Qianqian Wang and Sai Bi and Kai Zhang and Kalyan Sunkavalli and Shubham Tulsiani and Hanwen Jiang},
booktitle = {CVPR},
year = {2026}
}The work is partially done during Qitao Zhao's internship at Adobe Research.
This work was also supported by Intelligence Advanced Research Projects Activity (IARPA) via Department of Interior/Interior Business Center (DOI/IBC) contract number 140D0423C0074. The U.S. Government is authorized to reproduce and distribute reprints for Governmental purposes notwithstanding any copyright annotation thereon. Disclaimer: The views and conclusions contained herein are those of the authors and should not be interpreted as necessarily representing the official policies or endorsements, either expressed or implied, of IARPA, DOI/IBC, or the U.S. Government.