Current Structure-from-Motion (SfM) methods typically follow a two-stage pipeline, combining learned or geometric pairwise reasoning with a subsequent global optimization step. In contrast, we propose a data-driven multi-view reasoning approach that directly infers 3D scene geometry and camera poses from multi-view images. Our framework, DiffusionSfM, parameterizes scene geometry and cameras as pixel-wise ray origins and endpoints in a global frame and employs a transformer-based denoising diffusion model to predict them from multi-view inputs. To address practical challenges in training diffusion models with missing data and unbounded scene coordinates, we introduce specialized mechanisms that ensure robust learning. We empirically validate DiffusionSfM on both synthetic and real datasets, demonstrating that it outperforms classical and learning-based approaches while naturally modeling uncertainty.
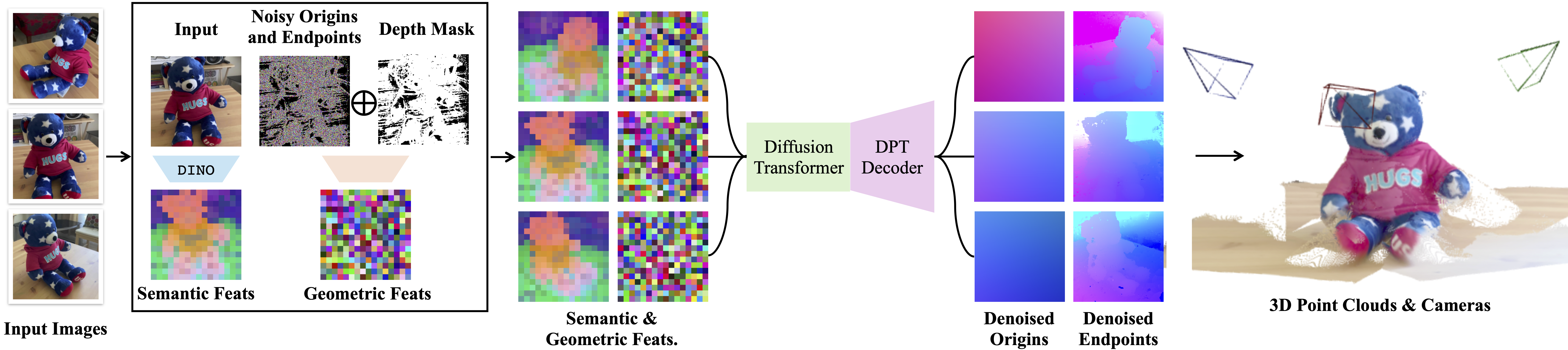
Given sparse multi-view images as input, DiffusionSfM predicts pixel-wise ray origins and endpoints in a global frame using a denoising diffusion process. For each image, we compute patch-wise embeddings with DINOv2 and embed noisy ray origins and endpoints into latents using a single downsampling convolutional layer, ensuring alignment with the spatial footprint of the image embeddings. We implement a Diffusion Transformer architecture that predicts clean ray origins and endpoints from noisy samples. A convolutional DPT head outputs full-resolution denoised ray origins and endpoints. To handle incomplete ground truth (GT) during training, we condition the model on a GT mask. At inference, the GT mask is set to all ones, enabling the model to predict origins and endpoints for all pixels. The predicted ray origins and endpoints can be directly visualized in 3D or post-processed to recover camera extrinsics, intrinsics, and multi-view consistent depth maps.







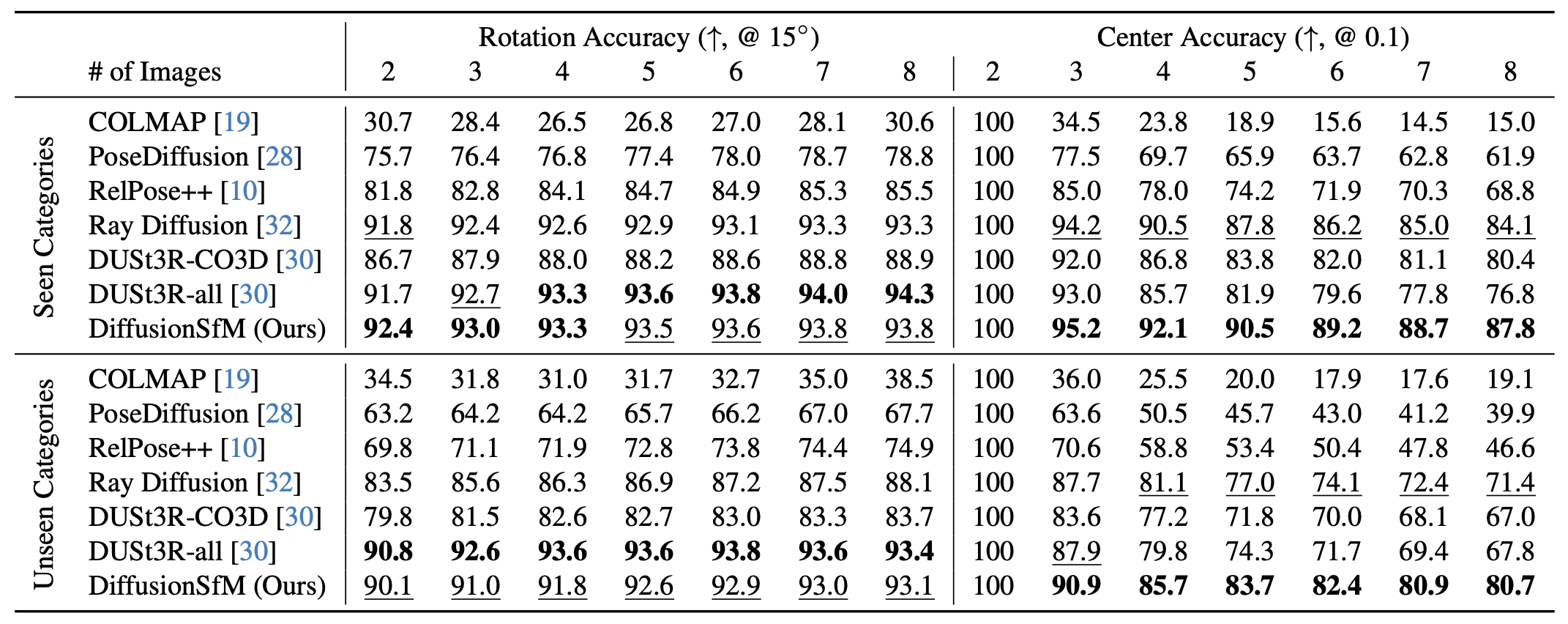
On the left, we report the proportion of relative camera rotations within 15° of the ground truth. On the right, we report the proportion of camera centers within 10% of the scene scale. To align the predicted camera centers to ground-truth, we apply an optimal similarity transform, hence the alignment is perfect at N=2 but worsens with more images. DiffusionSfM outperforms all other methods for camera center accuracy, and outperforms all methods trained on equivalent data for rotation accuracy.
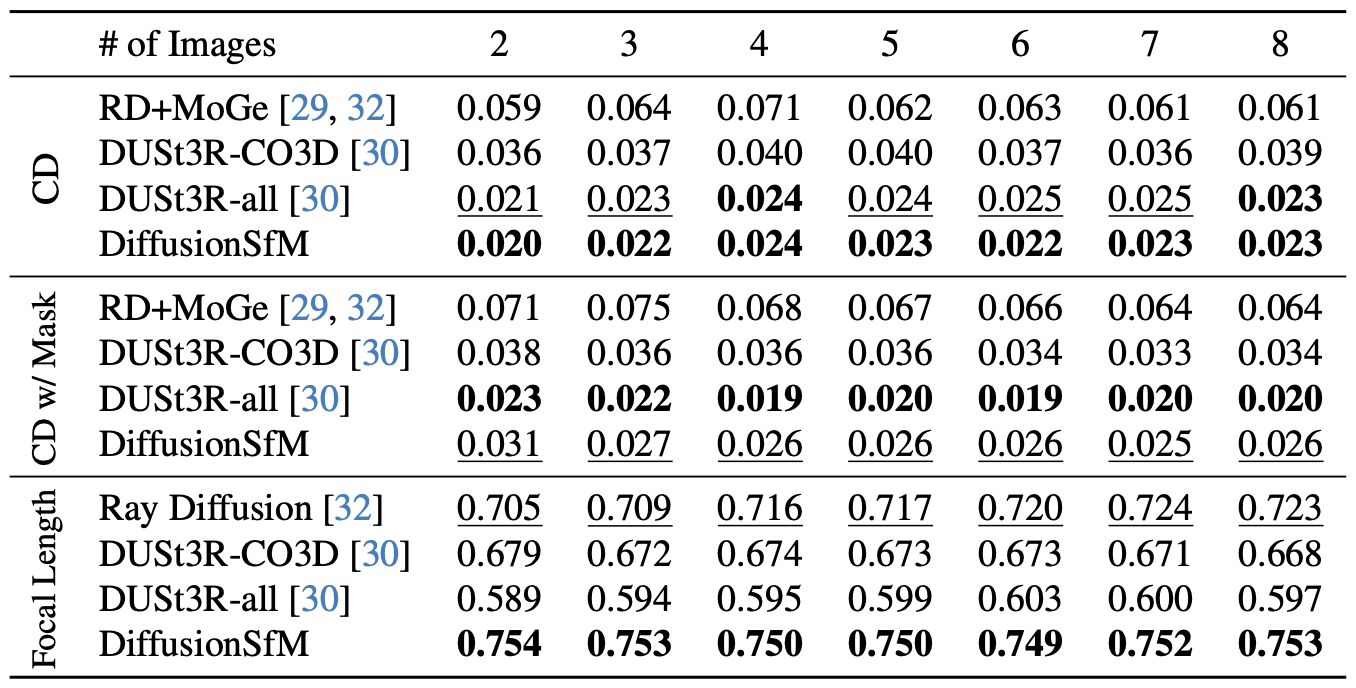
Top: CD computed on all scene points. Bottom: CD computed on foreground points only. Models marked with "*" are trained on CO3D only, while those without are trained on multiple datasets. Note that top and bottom values are not directly comparable, as each ground-truth point cloud is individually normalized.
Top: Habitat (2–5 views). Bottom: RealEstate10k (2, 4, 6, 8 views). Each grid reports camera rotation accuracy (left) and center accuracy (right). While DiffusionSfM performs on par with DUSt3R in rotation accuracy, it consistently surpasses DUSt3R in center accuracy.

DiffusionSfM demonstrates robust performance even with challenging inputs. Compared to DUSt3R, which sometimes fails to register images in a consistent manner, DiffusionSfM consistently yields a coherent global prediction. Additionally, while we observe that DUSt3R can predict highly precise camera rotations, it often struggles with camera centers (see the backpack example). Input images depicting scenes are out-of-distribution for RayDiffusion, as it is trained on CO3D only.
We present DiffusionSfM and demonstrate that it recovers accurate predictions of both cameras and geometry from multi-view inputs. Although our results are promising, several challenges and open questions remain.
Notably, DiffusionSfM employs a pixel-space diffusion model, in contrast to the latent-space models adopted by state-of-the-art T2I generative systems. Operating in pixel space may require greater model capacity, yet our current model remains relatively small -- potentially explaining the noisy patterns observed along object boundaries. Learning an expressive latent space for ray origins and endpoints by training a VAE could be a promising direction for future work. In addition, the computational requirement in multi-view transformers scales quadratically with the number of input images: one would require masked attention to deploy systems like ours for a large set of input images.
Despite these challenges, we believe that our work highlights the potential of a unified approach for multi-view geometry tasks. We envision that our approach can be built upon to train a common system across related geometric tasks, such as SfM (input images with unknown origins and endpoints), registration (some images have known origins and endpoints, whereas others don't), mapping (known rays but unknown endpoints), and view synthesis (unknown pixel values for known rays).
@inproceedings{zhao2025diffusionsfm,
title={DiffusionSfM: Predicting Structure and Motion via Ray Origin and Endpoint Diffusion},
author={Qitao Zhao and Amy Lin and Jeff Tan and Jason Y. Zhang and Deva Ramanan and Shubham Tulsiani},
booktitle={CVPR},
year={2025}
}We thank the members of the Physical Perception Lab at CMU for their valuable discussions, and extend special thanks to Yanbo Xu for his insights on diffusion models.
This work used Bridges-2 at Pittsburgh Supercomputing Center through allocation CIS240166 from the Advanced Cyberinfrastructure Coordination Ecosystem: Services & Support (ACCESS) program, which is supported by National Science Foundation grants #2138259, #2138286, #2138307, #2137603, and #2138296. This work was supported by Intelligence Advanced Research Projects Activity (IARPA) via Department of Interior/Interior Business Center (DOI/IBC) contract number 140D0423C0074. The U.S. Government is authorized to reproduce and distribute reprints for Governmental purposes notwithstanding any copyright annotation thereon. Disclaimer: The views and conclusions contained herein are those of the authors and should not be interpreted as necessarily representing the official policies or endorsements, either expressed or implied, of IARPA, DOI/IBC, or the U.S. Government.